Die Lösung
Die Lösung drehte sich um die gemeinsame Nutzung von Amazon Simple Storage Service(Amazon S3) und Anpassungen an der Pipeline, die auf unstrukturierten Daten (wie Video, Audio und Freiformtext) trainiert. Die von AWS verfeinerte Lösung zeigte ein klares Muster für eine deutliche Reduzierung der Komplexität, der Kosten und der zentralen Verwaltung des zweiten Schritts (wenn es um die Eingaben von Datenwissenschaftlern/Ingenieuren geht).
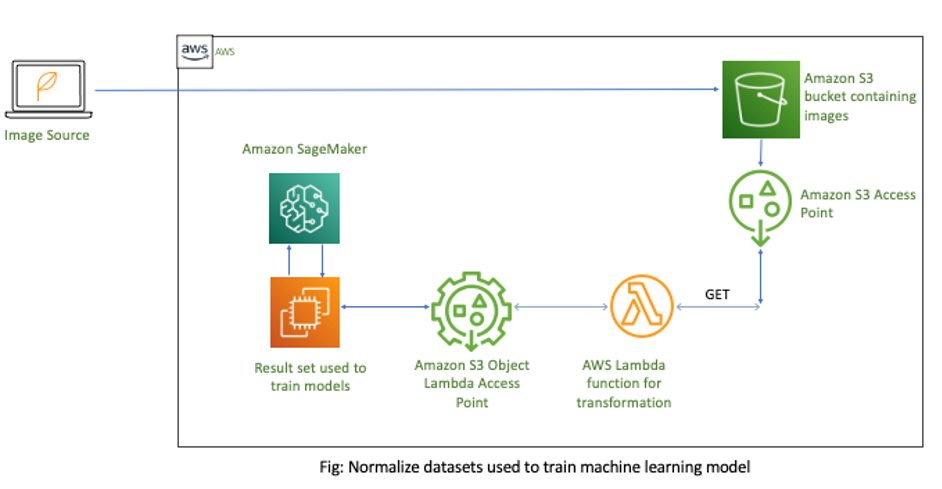
Die grundlegende Infrastruktur, insbesondere die Normalisierung von Datensätzen, die zum Trainieren von Machine Learning-Modellen verwendet werden.
So funktioniert die „elegante“ Lösung von AWS
„Wenn ML-Algorithmen unstrukturierte Daten wie Bilder und Videos verarbeiten, sind verschiedene Normalisierungsaufgaben (wie Grauskalierung und Größenänderung) erforderlich. Dieser Schritt dient dazu, die Konvergenz des Modells zu beschleunigen, eine Überanpassung zu vermeiden und die Vorhersagegenauigkeit zu verbessern. Sie führen diese Vorverarbeitungsschritte oft an Instanzen durch, die später das KI-Training durchlaufen. Dieser Ansatz führt zu Ineffizienzen, da diese Ressourcen in der Regel über teurere Prozessoren (z. B. GPUs) verfügen, als für diese Aufgaben erforderlich sind. Stattdessen externalisiert unsere Lösung diese Vorgänge über wirtschaftliche, horizontal skalierbare Amazon S3 Object Lambda-Funktionen.
Dieses Designmuster hat drei entscheidende Vorteile. Zunächst zentralisiert es die gemeinsamen Datenumwandlungsschritte, wie die Bildnormalisierung und die Beseitigung von ML-Pipeline-Code-Duplikationen. Zweitens vermeiden die S3 Object Lambda-Funktionen durch JIT-Konvertierungen Datenkonsistenzprobleme bei abgeleiteten Daten. Und schließlich reduziert die serverlose Infrastruktur den betrieblichen Overhead, erhöht die Zugriffszeit und begrenzt die Kosten auf die Zeit pro Millisekunde bei der Ausführung Ihres Codes.
Es gibt eine elegante Lösung, bei der Sie diese Datenvorverarbeitungs- und Datenkonvertierungsvorgänge mit S3 Object Lambda zentralisieren können. S3 Object Lambda ermöglicht es Ihnen, Code hinzuzufügen, der Daten aus Amazon S3 verändert, bevor er sie an eine Anwendung zurückgibt. Der Code wird innerhalb einer AWS Lambda-Funktion ausgeführt, einem serverlosen Rechenservice. Lambda kann sofort auf Zehntausende von parallelen Läufen skalieren und unterstützt Dutzende von Programmiersprachen und sogar benutzerdefinierte Container.“ – AWS Team für Lösungsarchitektur
Ajish Palakadan, Chief Technology Officer bei Firemind, sagt: „Als ML- und KI-Spezialist freuen wir uns, Amazon SageMaker auf neue und spannende Weise zu nutzen. Kostenreduzierung ist immer ein wichtiger Teil eines Kundenprojekts, und die Nutzung der neuesten Lösungen, um dies zu ermöglichen, ist das, was uns von anderen unterscheidet.“ Ajish Palakadan, Chief Technology Officer bei Firemind
Die feinen Details
Bei der im obigen Infrastrukturdiagramm dargestellten Lösung enthält der S3-Bucket die zu verarbeitenden Rohbilder. Anschließend müssen Sie einen S3 Access Point für die Bilder erstellen. Wenn Sie mehrere Ebenen von Modellen für maschinelles Lernen erstellen, sollten Sie für jedes Modell einen eigenen S3 Access Point anlegen.
Alternativ unterstützen die AWS Identity and Access Management (IAM)-Richtlinien für Zugangspunkte die gemeinsame Nutzung wiederverwendbarer Funktionen in ML-Pipelines. Dann hängen Sie eine Lambda-Funktion mit Ihrer vorverarbeitenden Geschäftslogik an den S3 Access Point. Nachdem Sie die Daten abgerufen haben, rufen Sie den S3 Access Point auf, um JIT-Datentransformationen durchzuführen. Schließlich aktualisieren Sie Ihr ML-Modell, um den neuen S3 Object Lambda Access Point zum Abrufen von Daten aus Amazon S3 zu verwenden.
Der ursprüngliche Artikel führt Sie dann durch die Erstellung des S3 Object Lambda-Zugangspunkts und erläutert die typischen Kosteneinsparungsanalysen, die die Ineffizienzen der Standardmodellschulung berücksichtigen. Wir empfehlen Ihnen, sich den Artikel anzuschauen und sich Zugang zu der scrollbaren Python-Sprache zu verschaffen (die Ihnen hilft, eine Lambda-Funktion zu erstellen, die die Anpassung und Konvertierung der Bilder vornimmt).