Generative KI (kurz GenAI) ist eine Teilmenge des maschinellen Lernens. Die Modelle von GenAI können lernen und komplizierte Muster in riesigen Datensätzen aufdecken. Diese Datensätze können Bilder, numerische Datensätze, Audiodaten, Sensordaten und vieles mehr sein!
Große Sprachmodelle (Large Language Models, LLMs) sind ein wichtiger Teil der GenAI-Auflösung und der Hauptgrund für den jüngsten Anstieg des Interesses an diesem Bereich der künstlichen Intelligenz. LLMs wurden über einen langen Zeitraum hinweg auf enorm großen Textdatensätzen aus dem gesamten Internet trainiert – was wiederum einen großen Bedarf an Rechenleistung mit sich bringt.
LLMs haben bewiesen, dass sie in der Lage sind, Material zu verstehen, komplizierte Aufgaben zu dekonstruieren und Probleme durch logisches Denken zu lösen. All dies ist auf die enorme Größe dieser Modelle zurückzuführen, die Milliarden (und manchmal Billionen) von trainierbaren und hochgradig angepassten Parametern haben können.
Es gibt verschiedene Arten von LLMs, obwohl sie alle auf demselben Forschungspapier basieren: „Attention is all you need“ (2017). Das ursprüngliche Modell bestand aus einem zusammenhängenden Satz von Kodierern und Dekodierern und beinhaltete einen neuartigen Mechanismus namens Aufmerksamkeit (wie im Titel der Arbeit angedeutet). Das Ziel der Arbeit war es, eine Übersetzungsaufgabe zu lösen, oder anders gesagt, eine Sequenz-zu-Sequenz-Aufgabe.
Während die ursprüngliche Architektur sowohl die Encoder- als auch die Decoder-Komponente verwendet, gibt es noch andere Varianten, die wir jetzt untersuchen werden:
Modelle nur mit Encoder
Bei reinen Encoder-Modellen wird nur der erste Teil des Transformers-Modells verwendet (wie der Name schon sagt). Sie werden auch als Auto-Encoding-Modelle bezeichnet.
Die Art und Weise, wie diese Modelle trainiert werden, ist die Verwendung einer Technik namens Mask Language Modelling. Bei dieser Technik wird ein zufälliges Token aus der Eingabesequenz durch ein neues spezielles Token namens < MASK > ersetzt, und das Ziel des Encoder-only LLM ist es, das maskierte Wort vorherzusagen. Sie bezeichnen diesen Prozess als Denoising-Prozess.
Zum Beispiel:
Diese Modelle erstellen bidirektionale Repräsentationen der Eingabesequenz, d.h. sie betrachten die Token vor und nach dem maskierten Token, um Vorhersagen zu treffen.
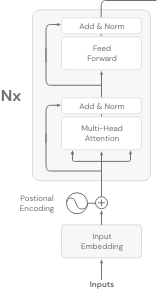
Nur-Encoder-Modelle sind eine gute Wahl, wenn die Aufgabe ein vollständiges Verständnis des Eingabesatzes erfordert. Zum Beispiel:
– Sentiment-Analyse
– Entity-Erkennung
– Wortklassifizierung
Beispiele für reine Drehgebermodelle:
– BERT
– ROBERTA
Modelle, die nur Decoder enthalten:
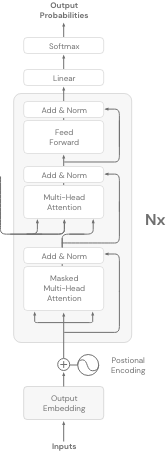
Decoder-Modelle verwenden nur den Decoder-Teil der Transformer-Architektur. Sie sind auch als autoregressive Modelle bekannt.
Das Ziel dieser Modelle ist es, das nächste Token anhand der vorherigen Token vorherzusagen. Im Gegensatz zu den reinen Encoder-Modellen bauen diese Modelle unidirektionale Repräsentationen des Eingabesatzes auf.
Diese Tabelle zeigt zum Beispiel, wie diese Modelle funktionieren. Die grünen Zellen stehen für die Eingabe, die gelben Zellen für das vorherzusagende Token und die roten Zellen für die zu ignorierenden Token.
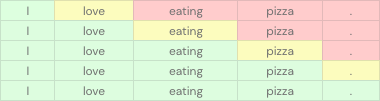
Decoder-Only-Modelle sind gut bei der Vorhersage des nächsten Wortes. Diese Modelle haben ihre Fähigkeiten jedoch auch bei anderen Aufgaben (Klassifizierung, Erkennung usw.) unter Beweis gestellt, indem sie Zero-Shot- und Little-Shot-Lernen verwendeten.
Beispiel für Modelle, die nur den Decoder verwenden:
– GPT-Familie
– BLOOM
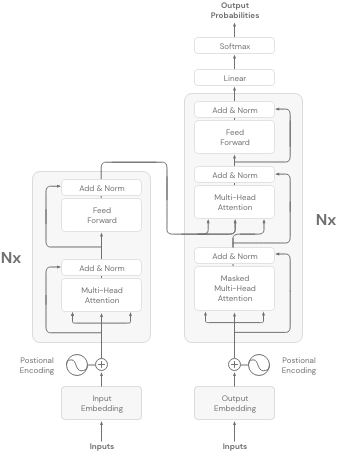
Encoder-Decoder-Modelle:
Die Encoder-Decoder-Modelle, oder anders gesagt, Seq-to-Seq-Modelle, verwenden sowohl den Encoder- als auch den Decoder-Teil der Transformer-Architektur. Das Ziel für diese Modelle variiert und hängt vom jeweiligen Modell ab.
Beliebte Anwendungsfälle für die Verwendung von Encoder-Decoder-Modellen sind:
– Übersetzung
– Zusammenfassung
– Beantwortung direkter Fragen
Hier sind einige beliebte Beispiele für Encoder-Decoder-Modelle:
– T5
– BART
Zum Schluss
Es gibt verschiedene Arten von Transformator-Architekturen, die in verschiedenen Branchen eingesetzt werden und jeweils für bestimmte Aufgaben nützlich sind. Jede von ihnen ist auf einen oder mehrere Bereiche spezialisiert. Daher müssen Sie sich bei der Wahl des Modells für dasjenige entscheiden, das zu Ihrer Anwendung und Ihren spezifischen Anwendungsfällen passt.
Glücklicherweise wissen unsere Teams bei Firemind sehr genau, wie man die richtigen Encoder- und Decoder-Modelle für Ihren Anwendungsfall einsetzt. Mit vorgefertigten internen Beschleunigern wie PULSE, die Ihre generative KI-Pipeline schnell beschleunigen können, sind wir Ihr bevorzugter Partner, wenn Sie den Sprung in einen GenAI-Workload wagen wollen.
Um mehr darüber zu erfahren, sprechen Sie hier mit unserem Team.