Lassen Sie uns eine vollautomatische, ereignisgesteuerte End-to-End-Pipeline für die Validierung der Datenqualität erstellen.
Das ist ein Untertitel, der uns begeistert! Wie bei jeder Datenreise ist es ein steiniger Weg, bis strukturierte, intelligente und leicht abfragbare Daten entstehen.
AWS Glue DataBrew ist ein visuelles Datenaufbereitungstool, mit dem Sie ganz einfach Datenqualitätsstatistiken wie doppelte Werte, fehlende Werte und Ausreißer in Ihren Daten finden können. Sie können in DataBrew auch Regeln für die Datenqualität einrichten, um bedingte Prüfungen auf der Grundlage spezieller Geschäftsanforderungen durchzuführen.
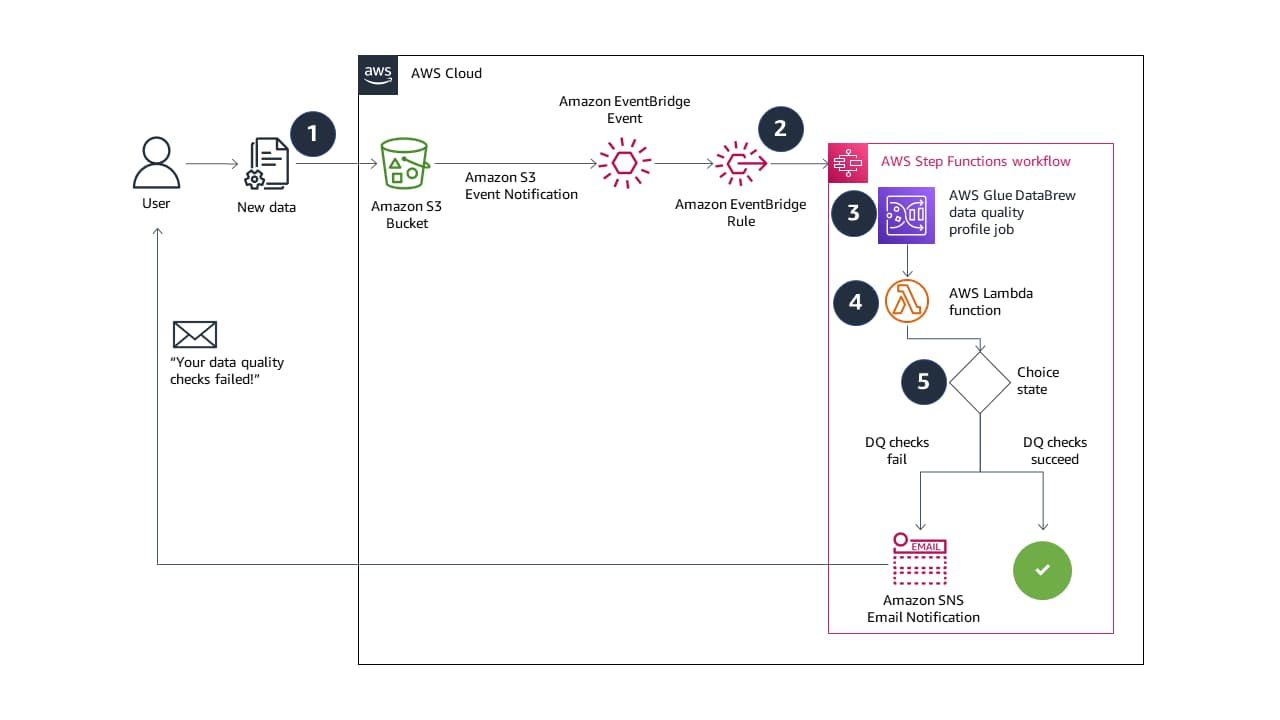
Architektur auf hoher Ebene, die AWS-Schrittfunktionsabläufe innerhalb von AWS hervorhebt.
Schritt für Schritt
Der Lösungsworkflow umfasst die folgenden Schritte:
1. Wenn Sie neue Daten in Ihren Amazon Simple Storage Service (Amazon S3) Bucket hochladen, werden Ereignisse an EventBridge gesendet.
2. Eine EventBridge-Regel löst die Ausführung eines Step Functions-Zustandsautomaten aus.
3. Der Zustandsautomat startet einen DataBrew-Profilauftrag, der mit einem Datenqualitätsregelsatz und Regeln konfiguriert ist. Wenn Sie erwägen, eine ähnliche Lösung aufzubauen, sollten der Ausgabeort des DataBrew-Profilauftrags und die S3-Quelldaten-Buckets eindeutig sein. Dies verhindert rekursive Auftragsläufe. Wir stellen unsere Ressourcen mit einer AWS CloudFormation-Vorlage bereit, die eindeutige S3-Buckets erstellt.
4. Eine Lambda-Funktion liest die Datenqualitätsergebnisse aus Amazon S3 und gibt eine boolesche Antwort in den Zustandsautomaten zurück. Die Funktion gibt false zurück, wenn eine oder mehrere Regeln im Regelsatz fehlschlagen und gibt true zurück, wenn alle Regeln erfolgreich sind.
5. Wenn die boolesche Antwort false ist, sendet der Zustandsautomat eine E-Mail-Benachrichtigung über Amazon SNS und der Zustandsautomat endet im Status failed. Wenn die boolesche Antwort wahr ist, endet der Zustandsautomat mit dem Status erfolgreich. Sie können die Lösung in diesem Schritt auch erweitern, um andere Aufgaben bei Erfolg oder Misserfolg auszuführen. Wenn zum Beispiel alle Regeln erfolgreich sind, können Sie eine EventBridge-Nachricht senden, um einen weiteren Transformationsauftrag in DataBrew auszulösen.
Die genauen technischen Schritte können Sie im Blogbeitrag hier nachlesen. AWS hat einen gründlichen und detaillierten Ansatz zum Testen dieser Lösung zusammengestellt und stellt sogar ein AWS Serverless Application Model(AWS SAM) und Beispielcode zur Verfügung.
Metin Alisho, Data Scientist bei Firemind, sagt: „Ereignisgesteuerte Pipelines sind das ‚Brot und Butter‘ vieler unserer Kundenlösungen. Mit dieser von AWS Glue DataBrew betriebenen Lösung ist es ganz einfach, Qualitätsdaten zwischen Ausreißern und doppelten Werten zu finden.“
Transformieren Sie Ihre Daten, eine Spalte nach der anderen!
Diese Lösungen, bei denen Tools wie AWS Glue DataBrew zum Einsatz kommen, sind erst der Anfang dessen, was bei der Datenverwaltung und -auswertung möglich ist. Setzen Sie sich noch heute mit uns in Verbindung, um herauszufinden, wie wir mit Ihren Daten arbeiten können.