In diesem Beitrag erfahren Sie, wie diese Modelle funktionieren. Wir betrachten die Prozesse der Tokenisierung, der Einbettung, des Trainings und der Feinabstimmung. Wir werden auch eine Reihe von Anwendungsfällen behandeln, von der Erstellung von Inhalten und Übersetzungen bis hin zu ausgefeilten Chatbots und Programmierassistenten.
Wie bei jedem mächtigen Werkzeug gibt es jedoch auch bei LLMs Herausforderungen und ethische Überlegungen, die nicht übersehen werden dürfen. Kritische Themen wie Voreingenommenheit, Fehlinformationen, Sicherheits- und Datenschutzbedenken und die mögliche Verdrängung von Arbeitsplätzen werden gegen Ende des Beitrags behandelt. Lesen Sie weiter, um mehr über die komplexe Welt der LLMs zu erfahren, ihre Möglichkeiten zu schätzen und ihre Grenzen zu erkennen.
Wie sie funktionieren
Die meisten der modernen LLMs, wie ChatGPT von OpenAI, basieren auf einer neuronalen Netzwerkarchitektur, die Transformers genannt wird. Transformatoren haben sich als besonders fähig erwiesen, Kontext in sequenziellen Daten wie Text zu erfassen. Die wichtigste Innovation der Transformers – der Aufmerksamkeitsmechanismus – ermöglicht eine parallele Verarbeitung, bei der alle eingegebenen Token gleichzeitig verarbeitet werden. Diese Funktion hilft Transformatoren, weitreichende Abhängigkeiten zu lernen, bei denen der Abstand zwischen einem Wort oder Satz und einem anderen nicht unbedingt proportional zu ihrer Relevanz ist. In dem Satz „Die Katze, die bereits einen Fisch gegessen hatte, war nicht hungrig“ würden die Transformatoren beispielsweise „verstehen“, dass „die Tat“ enger mit der Phrase „nicht hungrig“ verbunden ist, obwohl der Abstand zwischen ihr und „der Katze“ größer ist als zwischen ihr und „einem Fisch“.
Um ein leistungsfähiges Sprachmodell zu erhalten, müssen mehrere Schritte durchgeführt werden. Der erste davon ist die Aufbereitung der Textdaten, so dass sie für das Modell verständlich sind. Dieser Prozess wird als Tokenisierung bezeichnet, bei der der Eingabetext in einzelne Wörter, Teilwörter oder Zeichen zerlegt wird. Der Grad der Tokenisierung – Wörter, Teilwörter oder Zeichen – hängt von der Art der Sprache, den Eigenschaften des Modells, dem Umfang des Datensatzes und den Anforderungen der jeweiligen Aufgabe ab. Im Englischen zum Beispiel, wo Wörter oft durch Leerzeichen getrennt sind und der Umfang des Vokabulars überschaubar ist, kann die Tokenisierung auf Wortebene effizient sein. In Sprachen wie Chinesisch oder Japanisch hingegen, in denen die Wörter nicht durch Leerzeichen getrennt sind, könnte eine Tokenisierung auf Zeichenebene sinnvoller sein. Größere Datensätze ermöglichen eine Tokenisierung auf Wortebene, während kleinere Datensätze oft eine Tokenisierung auf Teilwort- oder Zeichenebene erfordern.
Nach der Tokenisierung werden diese Token in einem Prozess, der als Einbettung bekannt ist, auf numerische Vektoren abgebildet. Diese Vektoren oder Einbettungen repräsentieren Wörter in einem hochdimensionalen Raum, in dem die Lage und der Abstand zwischen den Vektoren die semantische Bedeutung erfasst. So werden beispielsweise Vektoren für Wörter mit ähnlichen Bedeutungen näher beieinander platziert. Diese Methode ermöglicht es dem Modell, die Bedeutungsnuancen und den Kontext zwischen verschiedenen Wörtern zu verstehen und zu erfassen. Die Einbettungen werden nicht manuell zugewiesen, sondern während des Modelltrainings erlernt und kontinuierlich angepasst, um die kontextuellen Beziehungen zwischen den Wörtern besser darzustellen.
Der nächste Schritt ist das Trainieren des Modells anhand der tokenisierten Einbettungen. Das Training ist ein entscheidender Teil des Prozesses, der es LLMs ermöglicht, kohärenten und kontextuell relevanten Text zu erzeugen. In dieser Phase lernen diese Modelle die komplizierten Muster der Sprache, so dass sie in der Lage sind, menschenähnlichen Text zu verstehen und nachzubilden.
Das Training eines LLM ist eine überwachte Lernaufgabe. Das Modell wird mit einem riesigen Datensatz gefüttert, der aus unzähligen Sequenzen von Token besteht. Jede Sequenz dient als Beispiel, aus dem das Modell lernen kann. Ziel ist es, dass das Modell lernt, das nächste Token in einer Sequenz vorherzusagen, wenn alle vorherigen Token vorhanden sind.
Der Datensatz, der zum Trainieren dieser Modelle verwendet wird, besteht normalerweise aus einem großen Textkorpus. Er kann Bücher, Websites, Artikel und andere Formen von geschriebenem Text enthalten. Je größer und vielfältiger der Datensatz ist, desto besser kann das Modell die verschiedenen Nuancen der menschlichen Sprache lernen.
LLMs haben viele Millionen oder sogar Milliarden von Parametern – das sind die Teile des Modells, die aus den Daten gelernt werden. Zu Beginn des Trainings werden diese Parameter mit zufälligen Werten initialisiert. Während das Modell den Trainingsdaten ausgesetzt ist, passt es diese Parameter an, um die Differenz zwischen seinen Vorhersagen und den tatsächlichen Daten zu verringern. Dieser Anpassungsprozess wird von einer Funktion, der so genannten Verlustfunktion, gesteuert, die angibt, wie gut die Vorhersagen des Modells mit den tatsächlichen Daten übereinstimmen.
Die wichtigste Technik zur Anpassung der Modellparameter ist die Backpropagation, die in Verbindung mit einem Optimierungsalgorithmus wie dem stochastischen Gradientenabstieg verwendet wird. Einfach ausgedrückt: Backpropagation berechnet den Gradienten der Verlustfunktion in Bezug auf die Parameter des Modells und zeigt damit an, wie stark eine kleine Änderung der Parameter den Verlust beeinflussen würde. Die Parameter werden dann in der Richtung aktualisiert, die den Verlust verringert, d.h. die Genauigkeit der Vorhersagen des Modells erhöht.
Der Prozess der Aktualisierung der Parameter des Modells zur Minimierung des Verlusts wird über zahlreiche Iterationen hinweg wiederholt. Eine Iteration bedeutet, dass das Modell einen Datensatz verarbeitet und seine Parameter einmal aktualisiert. Eine Epoche hingegen bedeutet, dass das Modell den gesamten Datensatz einmal durchläuft. Das Training eines LLM umfasst in der Regel mehrere Epochen, was bedeutet, dass das Modell den gesamten Datensatz mehrfach sieht.
Eine zentrale Herausforderung beim Training ist die Vermeidung von Overfitting, d.h., dass das Modell die Trainingsdaten zu gut lernt und bei den ungesehenen Daten schlecht abschneidet. Techniken wie Regularisierung, Dropout und frühzeitiges Stoppen werden eingesetzt, um eine Überanpassung zu verhindern.
Das Ergebnis dieses strengen Trainingsprozesses ist ein Modell, das menschenähnlichen Text generieren, Fragen beantworten, Texte zusammenfassen, Sprachen übersetzen und Code schreiben kann. All das, indem es vorhersagt, was als nächstes in einer Abfolge von Token kommt.
Nach dem anfänglichen Training kann das Modell für bestimmte Aufgaben feinabgestimmt werden. Wenn Sie das Modell z.B. für einen medizinischen Chatbot verwenden möchten, können Sie es auf medizinische Textdaten abstimmen. Dadurch kann das Modell bei bestimmten Aufgaben besser abschneiden, als wenn es nur aus allgemeinen Textdaten lernen würde.
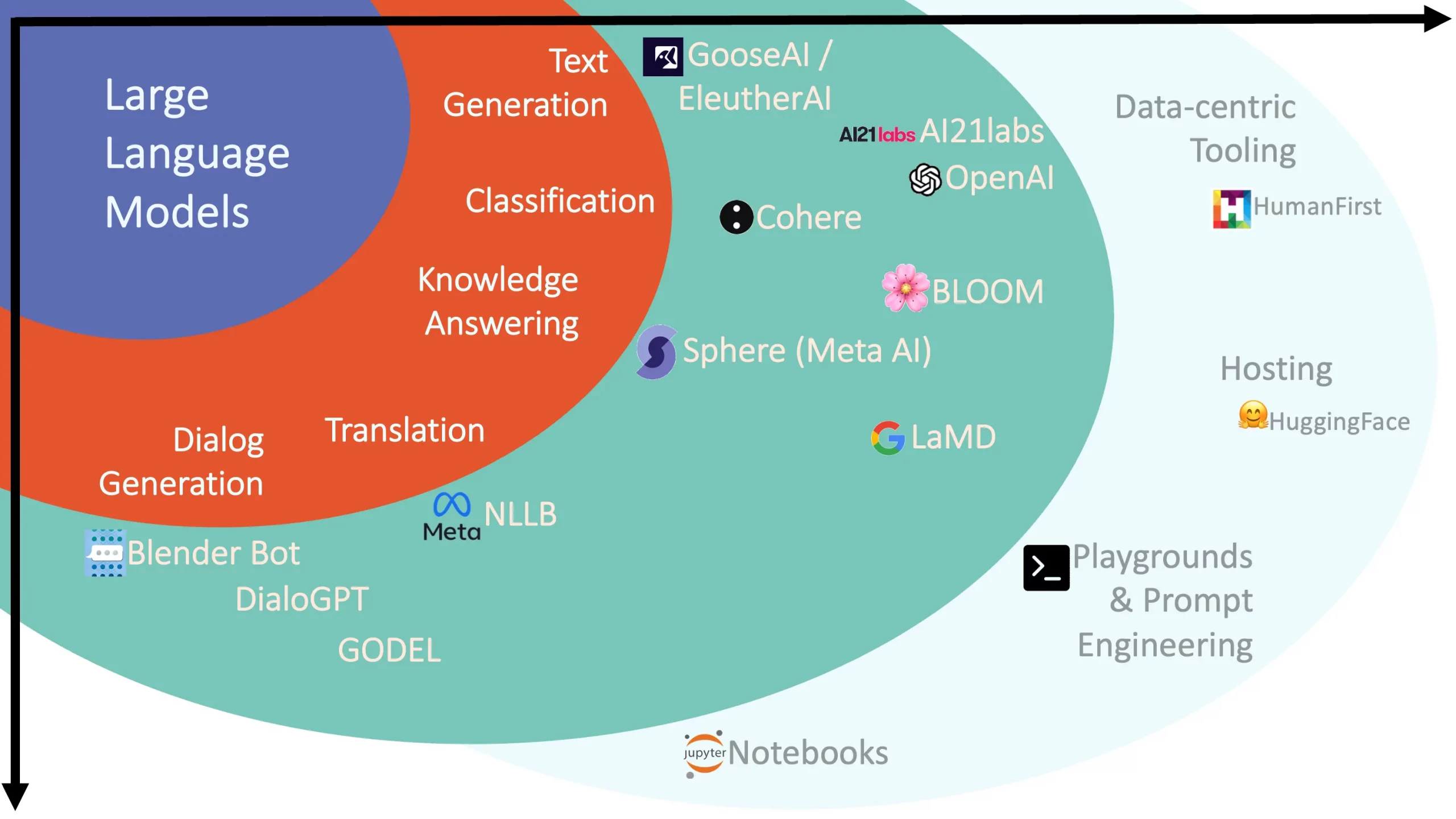
Anwendungsfälle
Die wichtigste Auswirkung von genAI ist natürlich ihre Fähigkeit, Inhalte zu generieren. Die rasche und weit verbreitete Einführung von ChatGPT und anderen generativen Modellen ist im Wesentlichen darauf zurückzuführen, dass sie uns mehr Zeit verschaffen. Mit ihren robusten Fähigkeiten, Text zu verstehen und zu generieren, können diese KI-Modelle eine Reihe von Inhalten produzieren – von Artikeln und Blogbeiträgen bis hin zu kreativen Geschichten und Gedichten. Sie sind in der Lage, Texte zu generieren, die dem menschlichen Schreiben sehr ähnlich sind, indem sie Tonalität, Stil und Kontext in ihre Ausgabe einbeziehen. Ganz gleich, ob Sie Hilfe beim Brainstorming benötigen, erste Versionen Ihrer Artikel verfassen möchten oder einfach nur ein Tool suchen, das Ihre Geschichte nach einer Aufforderung fortsetzen kann, LLMs sind ein leistungsstarkes Werkzeug. Sie können sogar Marketingtexte erstellen, E-Mails schreiben oder ansprechende Beiträge für soziale Medien verfassen. Sie können die menschliche Kreativität zwar nicht vollständig ersetzen, aber ihre Fähigkeit, schnell verschiedene Inhalte zu erstellen, kann eine wichtige Unterstützung sein, die Produktivität steigern und neue Ideen hervorbringen. Es ist, als ob Sie einen KI-gesteuerten Co-Autor zur Verfügung hätten, der jederzeit bereit ist, Sie bei Ihren kreativen Prozessen zu unterstützen.
LLMs haben die Fähigkeiten zur Beantwortung von Fragen revolutioniert. Da sie die komplizierten Nuancen der Sprache verstehen, können sie eine breite Palette von Fragen verstehen und genaue, kontextgerechte Antworten geben. Dies hat zu einer neuen Generation von Kundenservice-Bots geführt, die komplexe Anfragen bearbeiten können, wodurch sich die Notwendigkeit menschlichen Eingreifens verringert und die Antwortzeiten erheblich verbessert haben. Neben dem Kundenservice werden diese Modelle auch zur Entwicklung fortschrittlicher Tutorensysteme eingesetzt, die den Studenten personalisierte Antworten auf ihre Fragen geben können, ähnlich wie ein persönlicher Tutor, der auf Abruf zur Verfügung steht. Im Zuge der Weiterentwicklung der LLMs werden die Systeme zur Beantwortung von Fragen zwangsläufig noch ausgefeilter werden, so dass die Grenzen zwischen menschlichen und KI-gesteuerten Interaktionen weiter verschwimmen. Das ist ein vielversprechendes Zeichen für das transformative Potenzial, das diese Modelle bei der Neugestaltung der digitalen Kommunikation haben.
Chatbots, die von LLMs angetrieben werden, definieren die Dynamik der Mensch-Maschine-Interaktion neu. Diese fortschrittlichen Modelle verstehen und generieren Text, der der menschlichen Konversation sehr nahe kommt, und ermöglichen die Entwicklung natürlicher, interaktiver und ansprechender Chatbots. Ob es um die Beantwortung von Kundenanfragen, die Bereitstellung von Produktempfehlungen oder die Unterstützung bei Buchungen geht, LLM-gesteuerte Chatbots können eine Vielzahl von Aufgaben in verschiedenen Branchen übernehmen. Sie haben die Benutzererfahrung erheblich verbessert, indem sie rund um die Uhr sofortige und personalisierte Antworten liefern, ohne die typischen Einschränkungen eines von Menschen betriebenen Kundendienstes. Darüber hinaus sind diese intelligenten Chatbots in der Lage, auch bei längeren Gesprächen den Kontext aufrechtzuerhalten, so dass sich die Interaktionen weniger mechanisch und mehr wie ein menschliches Gespräch anfühlen. Mit der weiteren Verbesserung der LLMs können wir erwarten, dass Chatbots noch stärker in unsere täglichen digitalen Interaktionen integriert werden und effiziente, personalisierte und benutzerfreundliche Dienste anbieten.
Der Bereich der Sprachübersetzung hat mit der Einführung von LLMs ebenfalls erhebliche Fortschritte gemacht. Diese Modelle zeigen eine angemessene Kompetenz bei der Übersetzung von Texten von einer Sprache in eine andere. Dank ihres umfangreichen Trainings an verschiedenen und mehrsprachigen Datensätzen können sie unterschiedliche sprachliche Strukturen, Redewendungen und Kontexte erkennen und sich an diese anpassen. Auch wenn sie bei komplexen Texten noch nicht an die Präzision spezieller Übersetzungssysteme heranreichen, so liefern sie doch bei einfacheren, weniger technischen Texten schnelle Übersetzungen on-the-fly. Dies macht LLMs zu einem vielseitigen Werkzeug, das in der Lage ist, Sprachbarrieren zu überbrücken und eine reibungslosere sprachenübergreifende Kommunikation zu ermöglichen. Im Zuge der Weiterentwicklung dieser Modelle können wir davon ausgehen, dass sich ihre Übersetzungsfähigkeiten verbessern werden, wodurch sich möglicherweise neue Möglichkeiten für kontextbezogene Echtzeit-Übersetzungsdienste eröffnen.
LLMs sind auch im Bereich der Zusammenfassung sehr vielversprechend. Bei einem längeren Text können diese Modelle eine prägnante und kohärente Zusammenfassung erstellen, die die wichtigsten Punkte zusammenfasst. Das macht sie zu einem potenziellen Wegbereiter in einer Reihe von Bereichen. So können LLMs zum Beispiel lange Nachrichtenartikel in verdauliche Zusammenfassungen destillieren, die es dem Leser ermöglichen, die wichtigsten Informationen in einem Bruchteil der Zeit zu erfassen. Ebenso können LLMs in der akademischen Forschung oder bei Gerichtsverfahren, bei denen umfangreiche Dokumente gesichtet werden müssen, Zusammenfassungen erstellen, die die Kernargumente oder -ergebnisse hervorheben und so den Zeit- und Arbeitsaufwand für die Überprüfung erheblich reduzieren. Das wahre Potenzial dieser Anwendung ist enorm und erstreckt sich auf die Bereiche Journalismus, Wissenschaft, Recht, Wirtschaft und vieles mehr. Mit der Verfeinerung der Technologie könnte sich die Art und Weise, wie wir Informationen verwalten und konsumieren, weiterentwickeln und den Prozess effizienter und zugänglicher machen.
Eine weitere Anwendung von LLMs ist die Softwareentwicklung. Durch ihre Ausbildung an riesigen Codedatensätzen und natürlicher Sprache sind sie in der Lage, sowohl Code zu generieren als auch zu überprüfen. Dies ist ein unschätzbarer Vorteil für Entwickler. So können LLMs beispielsweise anhand einer ausführlichen Beschreibung einer Funktion einen groben Entwurf des entsprechenden Codes erstellen und so als Programmierassistent fungieren. Github hat eine Vorschau von Copilot X veröffentlicht, einem Paarprogrammierer, der auf dem Codex von OpenAI basiert. Copilot X wird in der Lage sein, Code in einer Reihe von verschiedenen Programmiersprachen zu vervollständigen, zu refaktorisieren, zu lintisieren und zu überprüfen. Bei der Codeüberprüfung können diese Modelle helfen, Fehler zu identifizieren, Verbesserungen vorzuschlagen und Stilrichtlinien durchzusetzen, was zur Qualität und Effizienz der Softwareentwicklung beiträgt. LLMs sind zwar noch nicht in der Lage, menschliche Entwickler zu ersetzen, aber sie können eine große Hilfe sein, indem sie Routineaufgaben automatisieren und Zeit für komplexere, kreative Problemlösungen freisetzen. Da diese Modelle kontinuierlich verfeinert und trainiert werden, wird ihr Einfluss auf die Softwareentwicklungslandschaft wahrscheinlich transformativ sein.
Herausforderungen und ethische Überlegungen
Eine der größten Herausforderungen bei LLMs ist das Risiko von Verzerrungen in ihren Ergebnissen. Diese Modelle lernen aus riesigen Datensätzen, die in der Regel aus dem Internet stammen und voreingenommene und voreingenommene Informationen enthalten können. Infolgedessen können die Modelle unwissentlich lernen und diese Voreingenommenheit aufrechterhalten. So können sie zum Beispiel eine geschlechtsspezifische Sprache erzeugen oder schädliche Stereotypen verstärken. Die Auswirkungen solcher Voreingenommenheiten können weitreichend sein, insbesondere wenn diese Modelle in Entscheidungsfindungssystemen oder zur Erstellung von Inhalten verwendet werden, die weit verbreitet sind. Die Bewältigung dieser Herausforderung erfordert gewissenhafte Anstrengungen bei der Datenkuration, dem Testen von Modellen und der Umsetzung von Maßnahmen zur Abschwächung festgestellter Verzerrungen.
Eine weitere große Herausforderung ist die mögliche Verbreitung von Fehlinformationen. LLMs erzeugen Inhalte auf der Grundlage von Mustern, die sie aus ihren Trainingsdaten gelernt haben, und verfügen nicht über ein inhärentes Verständnis oder eine Überprüfung der Wahrheit. Das bedeutet, dass diese Modelle, wenn sie dazu aufgefordert oder geneigt werden, Inhalte generieren könnten, die sachlich falsch oder irreführend sind. Dies ist aufgrund der schwerwiegenden Folgen, die Fehlinformationen haben können, ein kritisches Problem. Eine mögliche Lösung könnte darin bestehen, Mechanismen zur Gegenprüfung der generierten Inhalte mit zuverlässigen Datenquellen einzubauen, aber die Implementierung solcher Systeme ist alles andere als trivial.
Wie bei jeder Technologie, die mit Daten umgeht, insbesondere mit persönlichen oder sensiblen Daten, sind Sicherheit und Datenschutz von größter Bedeutung. Es ist von entscheidender Bedeutung, dass LLMs auf ethische und sichere Weise verwendet werden. Dazu gehört der Schutz der für die Ausbildung verwendeten Daten und die Wahrung der Privatsphäre in Anwendungen, bei denen Nutzerdaten eine Rolle spielen, wie z.B. in personalisierten Chatbots oder Empfehlungssystemen. Es geht auch um Bedenken hinsichtlich der böswilligen Verwendung von LLMs, z. B. bei der Erzeugung von Deepfake-Inhalten oder irreführenden Informationen.
Die Befürchtung, dass KI zu einer Verdrängung von Arbeitsplätzen führen könnte, ist eine weit verbreitete Sorge, und LLMs sind da keine Ausnahme. Da diese Modelle immer besser in der Lage sind, hochwertige Inhalte zu generieren und Aufgaben wie den Kundenservice zu übernehmen, besteht die Sorge, dass sie menschliche Arbeitsplätze in diesen Bereichen ersetzen könnten. KI kann zwar Routineaufgaben automatisieren, aber man darf nicht vergessen, dass sie auch neue Möglichkeiten und Rollen schafft, die es vorher nicht gab; denken Sie nur an den Aufstieg des Prompt-Engineering. Die Herausforderung besteht darin, diesen Übergang zu bewältigen, einschließlich der Bereitstellung der notwendigen Anpassungs- und Umschulungsmöglichkeiten, um den Menschen zu helfen, sich an die veränderte Arbeitswelt anzupassen.
Die Bewältigung dieser Herausforderungen und ethischen Erwägungen wird ein wichtiger Teil der Reise sein, wenn wir LLMs weiter entwickeln und einsetzen. Dies unterstreicht die Notwendigkeit einer multidisziplinären Zusammenarbeit zwischen Politikern, Forschern, Ethikern und Anwendern, um sicherzustellen, dass die Entwicklung dieser leistungsstarken Technologie von den Prinzipien der Fairness, Transparenz und Verantwortlichkeit geleitet wird.
Fazit
Wie wir bereits festgestellt haben, sind LLMs beeindruckende Instrumente mit enormem Potenzial, die bereits eine Vielzahl von Bereichen verändert haben. Sie sind jedoch kein Allheilmittel, und ihre Verwendung ist mit wichtigen Überlegungen in Bezug auf Voreingenommenheit, Fehlinformationen und andere ethische Bedenken verbunden. Da diese Modelle weiter verbessert und auf neue Art und Weise angewendet werden, ist es wichtig, diese Fragen im Auge zu behalten und sicherzustellen, dass die Technologie verantwortungsvoll entwickelt und genutzt wird.
Wir stehen noch ganz am Anfang, wenn es darum geht, das volle Potenzial von LLMs zu verstehen und zu nutzen. Mit weiterer Forschung, ethischen Richtlinien und praktischer Umsetzung versprechen diese Modelle, weiterhin bedeutende Fortschritte in der KI zu erzielen. Es ist eine aufregende Reise, und die Möglichkeiten sind so groß wie die kollektive Vorstellungskraft.
Wenn Sie mehr über Firemind und unser Engagement im Bereich der generativen KI erfahren möchten, besuchen Sie unsere Übersichtsseite hier für weitere Details.